 My Corner of the Web
My Corner of the Web
The Large Language Model Ecosystem is the ever-growing suite of ancillary technologies that support, enhance, and supplement the LLM. A good metaphor for the LLM ecosystem is that the LLM is the engine, and its surrounding technologies are all the other systems necessary to make the car functional (like the chassis, wheels, frame, etc.) as depicted below in Figure 1 (excuse Dall-E’s bad spelling).
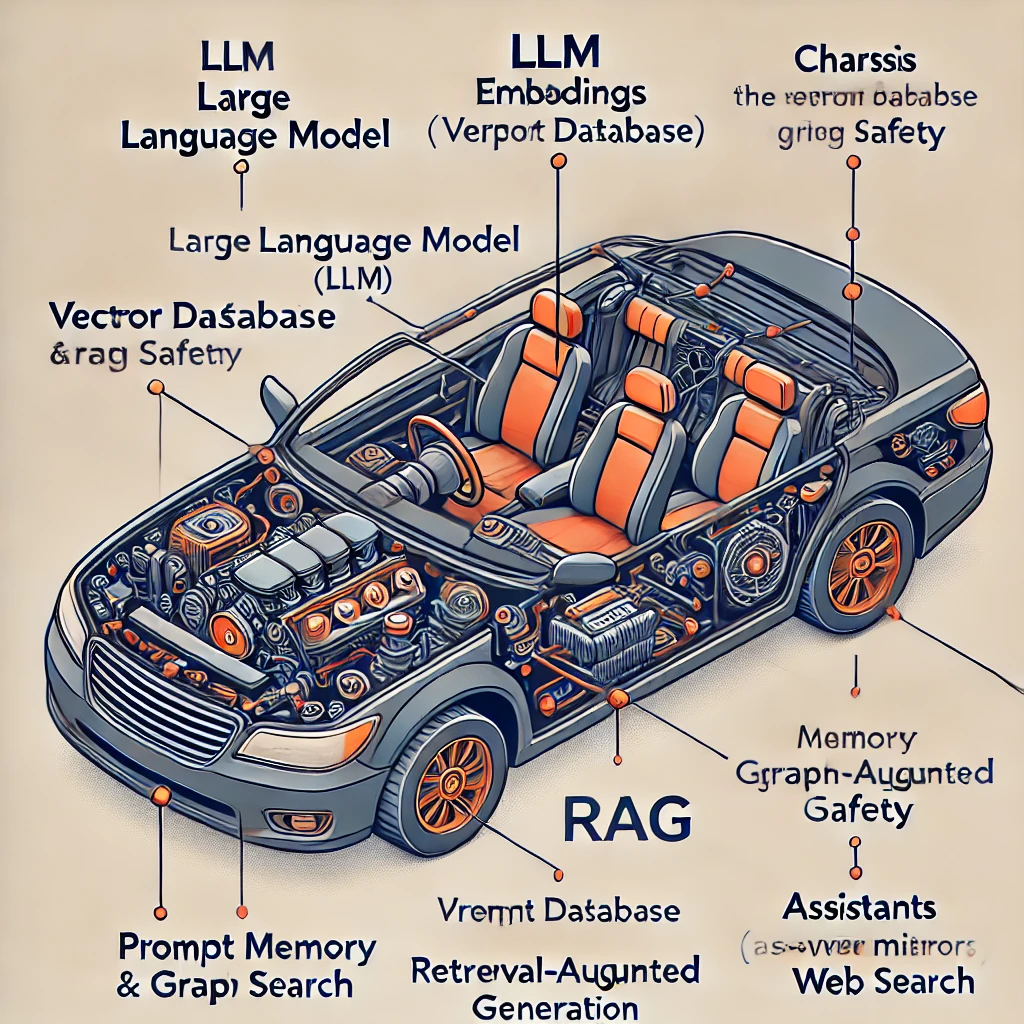
Figure 1 LLM Ecosystem (Image generated by Dalle-E)
While Figure 1 does not accurately represent the LLM ecosystem (I will provide more accurate diagrams later in the article), the Dall-E image does do a decent job of presenting the metaphor of the LLM as the engine to a car that is supported by other “ancillary systems”. An important question to consider as we examine each of these “ancillary” components, “Is this just an API land grab by the major players in order to attempt to lock-in developers to their platform or are these components an intrinsic part of LLM usage that is required for the primary use cases?”
Let’s examine each component and then see how they fit together:
· Large Language Model (LLM) — A neural network that accepts a sequence of tokens as input (may have a very large input window and max allowable tokens, which has become a point of competition between LLMs) and outputs the most probable next token in the sequence based on its training. It continues to output tokens until it either hits its max number of output tokens or the end of sequence (EOS).
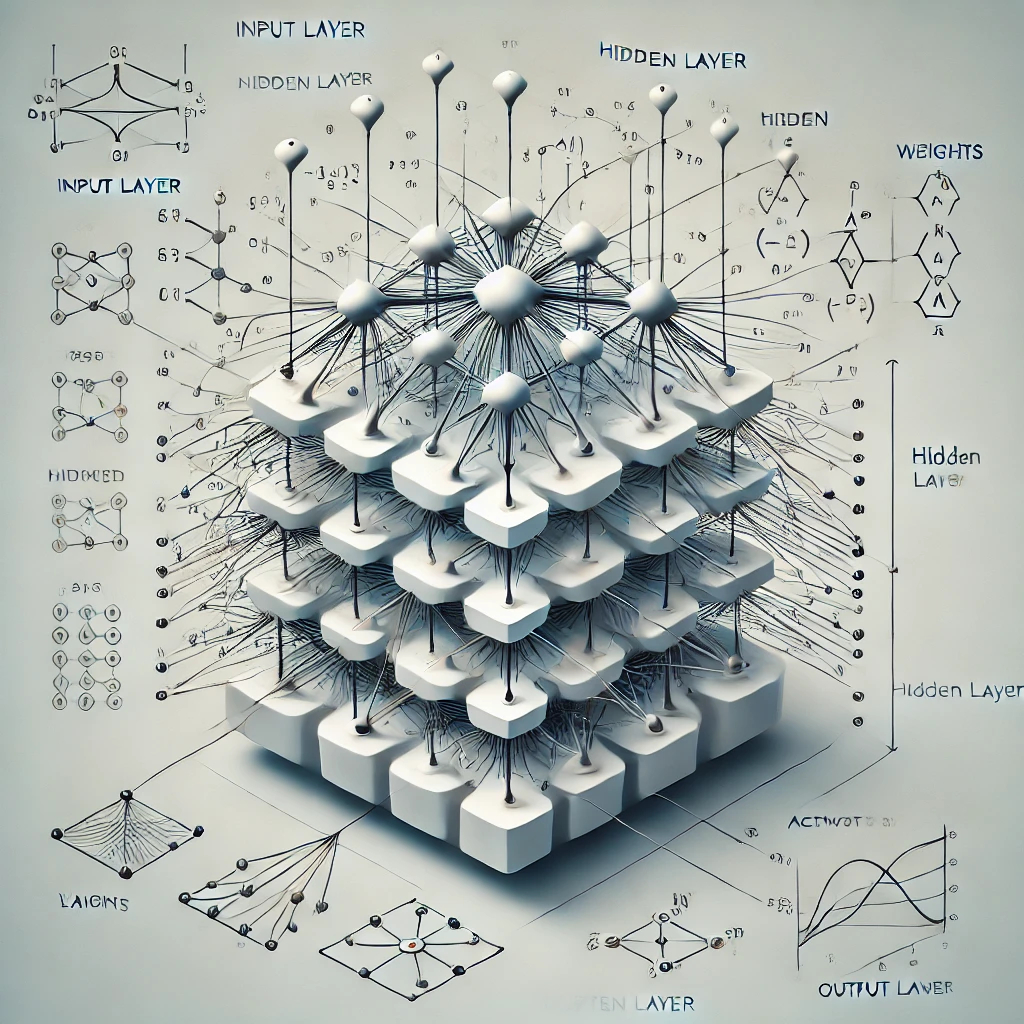
Figure 2 A Large Language Model (LLM) is a Neural Network
Figure 2 is Dalle-E’s interpretation of a neural network and it does a decent job of showing the connecting layers of simulated neurons. The important thing to understand in relation to a large language model is that it is a probabilistic deep learning technique that has been trained on billions of pages of text from the internet and has learned word patterns. It’s job is to take any sequence of input text and predict the next word in the sequence. Continue that until you have a complete sequence. My favorite analogy for a neural network is a sophisticated Pachinko machine (See figure 3), where the balls entering the top are the sequence of word with only a single ball (word) exiting the bottom.

Figure 3 Neural Network as a Software Pachinko Machine
Let’s complete our discussion by examining the inputs and outputs to/from a Large Language Model as depicted in Figure 4. As you can see, the interaction model with the LLM is very simple:
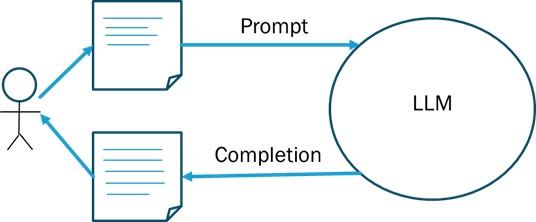
Figure 4 Interaction with the Large Language Model via an API
Examining Figure 4 from left to right (and back), we see that a User types a prompt into the interface and submits that prompt to the large language model. A prompt is simply some text that is as short as a sentence and as long as a paragraph or even an entire document (depending on the maximum input size of the LLM you are communicating with, for example, GPT-4o has an input size of 128,000 tokens). LLM’s use the term “tokens” for the input instead of words because tokens better handle subwords (including commonalities between languages) and shorten the vocabulary necessary. Table 1 is a simple table of words to token mappings.
Table 1 Words to Tokens
|
Word |
Tokens |
|
|
['un', 'believ', 'ably'] |
|
|
don't |
['do', "n't"] |
|
|
electroencephalogram |
['electro', 'encephalo', 'gram'] |
|
|
happiness |
['happi', 'ness'] |
|
|
felicidad |
['felici', 'dad'] |
Besides tokens there are multiple parameters you can pass into a Large Language Model to affect its behavior. One of the most important is called “Temperature” which affects the randomness (also called “creativity”) of the output (aka completion). We will examine all of the parameters to the most common LLM in future articles in this series as we examine each and every API for each component int the LLM ecosystem.
· Embeddings - a vector of floating-point numbers that represent a sequence of words in a "concept space." This is instrumental in prompt classification and retrieval-augmented generation (RAG). In both, an embedding is generated for the input prompt. Here is a sample embedding for the word “Cat” using the popular Word2Vec algorithm.
First embedding (for the word 'cat'):
[-0.001072 0.000473 0.010207 0.018019 -0.018606 -0.014234 0.012918
0.017946 -0.010031 -0.007527 0.014761 -0.003067 -0.009073 0.013108
-0.00972 -0.003632 0.005753 0.001984 -0.01657 -0.018898 0.014624
0.010141 0.013515 0.001526 0.012702 -0.006811 -0.001893 0.011537
-0.015043 -0.007872 -0.015023 -0.00186 0.019076 -0.014638 -0.004668
-0.003875 0.016155 -0.011862 0.00009 -0.009507 -0.019207 0.010015
-0.017519 -0.008784 -0.00007 -0.000592 -0.015322 0.019229 0.009964
0.018466]
And here is a 2 dimensional plot of the embeddings of a random set of words.
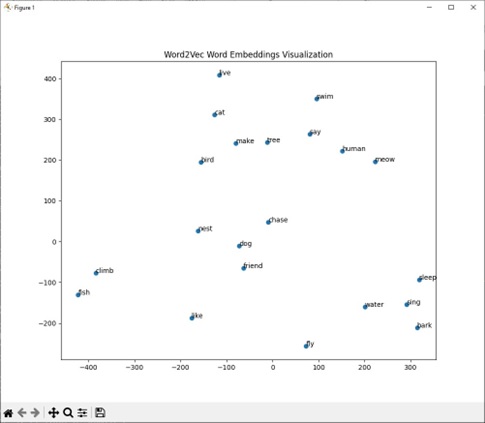
Figure 5 Word2Vec Embeddings Visualization
See the Code listings at the end of this article for the python program that generates and plots those embeddings.
There are many different techniques for generating these embeddings and this is an active area of research. The latest techniques all involve using neural networks trained on large bodies of text to generate these vectors. Those vectors of numbers (aka embeddings) can then be used to match a prompt to a set of text chunks in a vector database to find content (from your data) that is relevant to the prompt.
· Vector Databases - A vector database is a text database that stores "chunks" of text and an embedding (each positioned vector) for that chunk in order to retrieve the chunks similar to a prompt (using its embedding) from the user. These chunks can be used as input to an LLM in a RAG implementation pattern (you will see its role in the RAG process when we define and diagram RAG below).
There are numerous vector databases available (and more entering the fray every day). Postgresql (a popular open source database) has a free extension called pgvector that enables Postgresql to function as a vector database.
· Retrieval Augmented Generation (RAG) — An architectural pattern used to allow LLMs to answer questions from your own data (e.g., BYOD strategy). As depicted in Figure 6, the maximum input size of tokens allows alignment of a prompt with textual snippets from a vector database in addition to the user's query. The interaction with the vector database uses an embedding for each semantic chunk of text to generate an embedding from the prompt. The search in a vector database involves finding text chunk embeddings similar to the prompt embeddings.
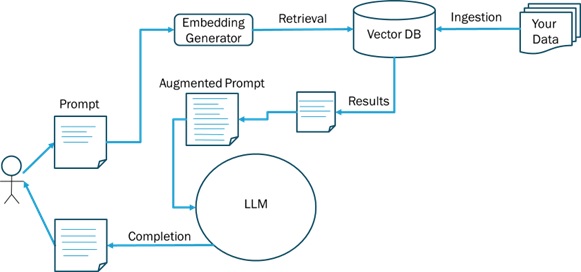
Figure 6 Retrieval Augmented Generation and the LLM
As you can see in Figure 6, the original prompt is not sent to the LLM, instead, the prompt augmented with the similar chunks from the Vector database is sent to the large language model.
· Prompt Memory — The ability for the chat interface to save past prompts to use as context for future similar prompts. It is important to understand that this is not a function of the LLM, instead it would be a function of the Chat user interface to save a prompt to provide additional context in a later prompt.
· Graph RAG — A variation on the RAG approach that adds the construction of a "knowledge graph" to help provide context to the text chunks retrieved from the vector database. This is an area of significant research. Microsoft recently released an initial implementation on GitHub (see: https://github.com/microsoft/graphrag). Neo4j is a graph database company that also offers a solution in this area (see: https://neo4j.com/developer-blog/knowledge-graph-rag-application/)
· Function Calling — The ability for the LLM to invoke custom functions (that a developer provides) to generate data to feed into the LLM.
· Guard Rails — These are checks on the LLM’s inputs and outputs to screen for illegal activity. Many LLMs offered by cloud providers have standard guard rails in place (see Microsoft guardrail discussion at https://azure.microsoft.com/en-us/blog/announcing-new-tools-in-azure-ai-to-help-you-build-more-secure-and-trustworthy-generative-ai-applications/). This is another area of active research.
· Web Search — It is important to understand that all large language models have a "knowledge cutoff" date that represents the end date from the data the model was trained on. So, how does the LLM answer any question after that cutoff date? The answer is to use an approach similar to RAG, but instead of retrieving content from the vector database, you augment the prompt with information retrieved from a search engine or web scraping the top hits. This solves the LLM "recency" problem.
· Assistants — A set of "helpers" to assist the large language model in complex, multi-step tasks. The premier example of this is "Code Interpreter," which is a technique for using the LLM’s code generation abilities to handle numerical data and various types of structured data (like numbers) that are not the forte of language models. This is the key technique used by ChatGPT to enable data analysis on uploaded Excel or CSV files. For example, ChatGPT will use the CodeInterpreter assistant to generate a budget pie chart from a spreadsheet. Here is OpenAI’s description of the CodeInterpreter API (see: https://platform.openai.com/docs/assistants/tools/code-interpreter).
· Other - here are some other optional components some vendors are adding to their LLM ecosystems:
o API integrations (i.e., weather, functions, collaboration, custom functions).
o Collaboration tools.
Now, we are ready to see the complete picture of the LLM Ecosystem as depicted in Figure 7.
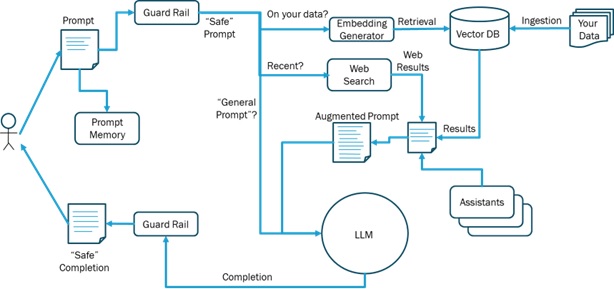
Figure 7 The LLM Ecosystem
Figure 7 shows all of the components we have discussed and the basic flows between them and the Large Language Model. The fact that this ecosystem is growing so rapidly is a double-edged sword for both developers and the public. For developers, it is difficult to keep up with this ecosystem and the rapidly changing Application Programming Interfaces that are evolving to incorporate these new components. Is this a “feature-war” by the LLM vendors to capture developer mindshare? The danger in an API land grab is that it delays essential standardization required for interoperability. This is similar to the path cloud vendors have taken in rapidly expanding their ecosystems to capture developer mindshare. In general, API landgrabs are bad for both the developers and the end-users because they involve lock-in to a single platform and that impedes the ability to switch to a new platform. As we know in economics, competition makes the entire industry better (better products at cheaper prices)... and customer lock-in is a vendor technique to thwart competition by creating a captive audience.
The next step in this article series will be to examine the details of each component’s Application Programing Interface (API) for various LLM/Cloud implementations of this Ecosystem! Stay tuned…
Code Listings
Listing 1: embedding1.py
# Import necessary libraries
from gensim.models import Word2Vec
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
import numpy as np
# Define a small corpus
sentences = [
['cat', 'say', 'meow'],
['dog', 'bark'],
['bird', 'sing'],
['fish', 'swim'],
['dog', 'chase', 'cat'],
['bird', 'fly'],
['cat', 'climb', 'tree'],
['fish', 'live', 'water'],
['dog', 'friend', 'human'],
['bird', 'make', 'nest'],
['cat', 'like', 'sleep'],
]
# Train the Word2Vec model
model = Word2Vec(sentences, vector_size=50, window=3, min_count=1, workers=4)
# Get the list of words in the vocabulary
words = list(model.wv.index_to_key)
# Get the embeddings for the words
word_vectors = model.wv[words]
# Set print options to avoid scientific notation
np.set_printoptions(precision=6, suppress=True)
# Print the first embedding (for the word 'cat')
print(f"First embedding (for the word '{words[0]}'):\n{word_vectors[0]}\n", flush=True)
# Reduce the dimensions using t-SNE with a lower perplexity
tsne = TSNE(n_components=2, random_state=42, perplexity=2) # Set perplexity to a value lower than number of words
word_vectors_2d = tsne.fit_transform(word_vectors)
# Plot the word vectors
plt.figure(figsize=(10, 8))
plt.scatter(word_vectors_2d[:, 0], word_vectors_2d[:, 1])
# Annotate the points with the words
for i, word in enumerate(words):
plt.annotate(word, xy=(word_vectors_2d[i, 0], word_vectors_2d[i, 1]))
plt.title("Word2Vec Word Embeddings Visualization")
plt.show()